算法
技术人生
husky
bootstrap
lua metatable
游戏
华为云
https
MQTT
自动驾驶
springboot
线性表
系统错误
多继承和菱形虚拟继承
svn
makefile
CAPL
批量替换
printf
深浅拷贝
聚类算法
2024/4/20 13:25:58
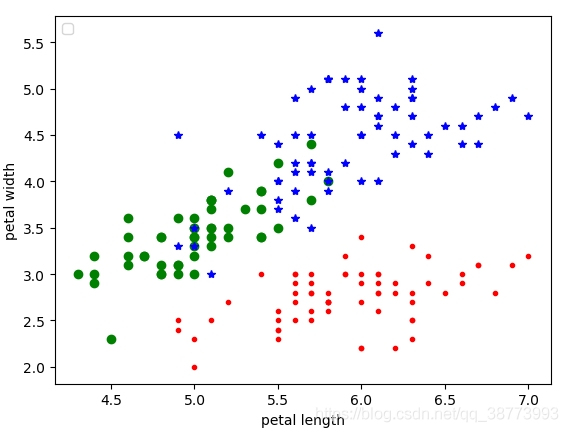
python实现K均值(K-Means分散性聚类)算法
#K均值(K-Means分散性聚类)算法
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import datasets
irisdatasets.load_iris()
xiris.data[:,:4] #取特征空间4个维度
print(x.shape)
plt.scatter(x[:,0],x[:,1],c"re…
python实现AGNES(凝聚层次聚类)算法
#AGNES(凝聚层次聚类)算法
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
from sklearn import datasets
from sklearn.metrics import confusion_matrix
irisdatasets.load_iris()
irisdatai…

python(sklearn) 聚类性能度量
文章目录python(sklearn) 聚类性能度量一、sklearn聚类评价函数:二、评价函数说明:1. 轮廓系数(Silhouette Coefficient)2. CH分数(Calinski Harabasz Score )3. 戴维森堡丁指数(DBI)——davies_bouldin_sc…

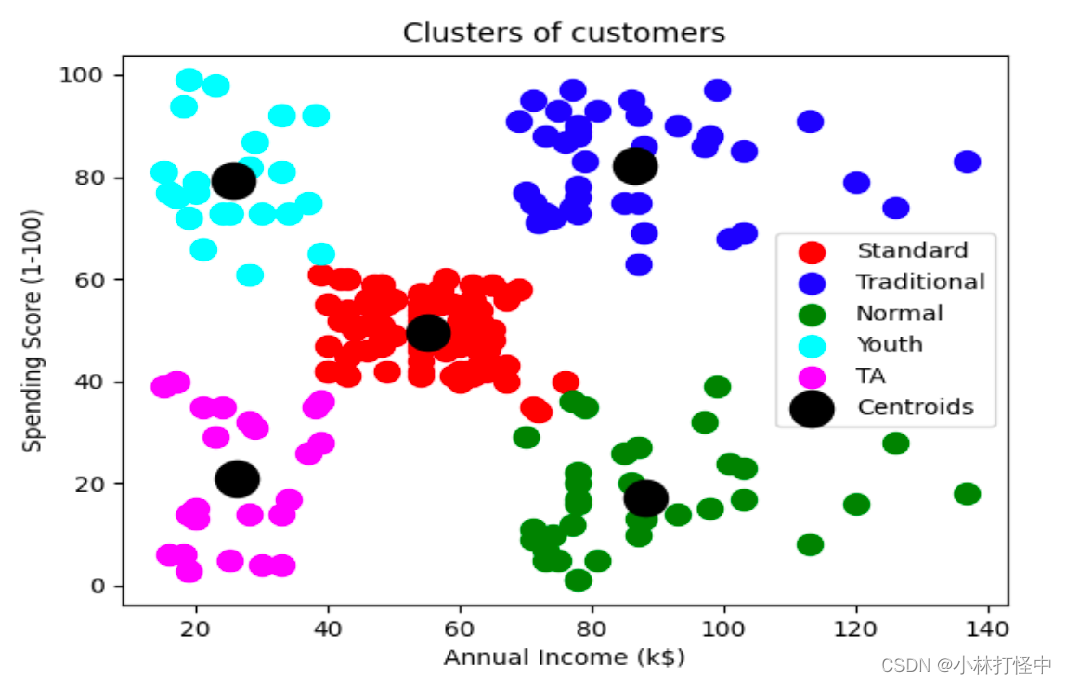
基于聚类的推荐算法笔记——以豆瓣电影为例(四)(附源代码)
基于聚类的推荐算法笔记——以豆瓣电影为例(四)(附源代码)
第一章 聚类算法介绍 基于聚类的推荐算法笔记一
第二章 数据介绍 基于聚类的推荐算法笔记二
第三章 实现推荐算法 基于聚类的推荐算法笔记三
第四章 评价推荐算法 基于聚类的推荐…
聚类算法(KMeans)模型评估方法(SSE、SC)及案例
一、概述 将相似的样本自动归到一个类别中,不同的相似度计算方法,会得到不同的聚类结果,常用欧式距离法;聚类算法的目的是在没有先验知识的情况下,自动发现数据集中的内在结构和模式。是无监督学习算法
二、分类
根据…

【文本聚类】三种聚类算法实现影评的情感分析(K-Means,Agglomerative,DBSCAN)
文本处理
from nltk.corpus import movie_reviews# ([...], pos)
# ([...], neg)
documents [(list(movie_reviews.words(fileid)), category) for category in movie_reviews.categories() for fileid in movie_reviews.fileids(category)]# 将documents「随机化」ÿ…
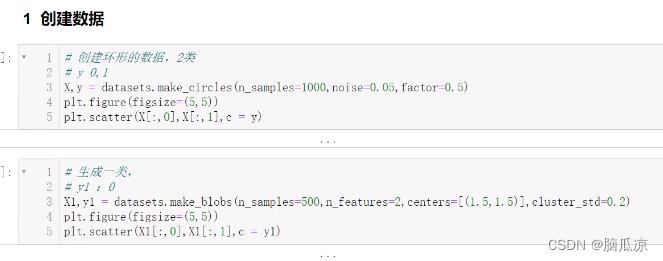
人工智能_机器学习088_DBSCAN聚类案例_KMeans聚类算法效果展示---人工智能工作笔记0128
然后我们先来看一下上一节的代码首先导包
import numpy as np 导入数学计算包
import matplotlib.pyplot as plt 导入画图包
from sklearn.cluster import KMeans,DBSCAN 导入算法
from sklearn import datasets 导入数据集包 然后我们再去创建数据
X,y = datasets.make_c…
【小沐学NLP】Python实现K-Means聚类算法(nltk、sklearn)
文章目录 1、简介1.1 机器学习1.2 K 均值聚类1.2.1 聚类定义1.2.2 K-Means定义1.2.3 K-Means优缺点1.2.4 K-Means算法步骤 2、测试2.1 K-Means(Python)2.2 K-Means(Sklearn)2.2.1 例子1:数组分类2.2.2 例子2࿱…

二分K-Means算法
二分K-Means算法是对K-Means算法的优化,主要优化的地方是在选取质心的时候,二分K-Means算法有效地避免了在初始选取质心时的误差,可以有效地提高算法效率。 测试数据:testSet2.txt 中间用tab分隔
3.275154 2.957587 -3.344465…
人工智能_机器学习076_Kmeans聚类算法_体验_亚洲国家队自动划分类别---人工智能工作笔记0116
我们开始来看聚类算法 可以看到,聚类算法,其实就是发现事物之间的,潜在的关联,把 有关联的数据分为一类 我们先启动jupyter notebook,然后 我们看到这里我们需要两个测试文件 AsiaFootball.txt里面记录了,3年的,亚洲足球队的成绩
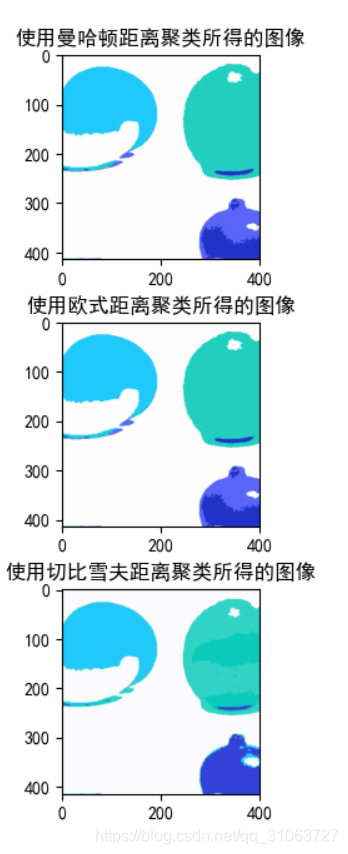
基于Python——Kmeans聚类算法的实现
1、概述
本篇博文为数据挖掘算法系列的第一篇。现在对于Kmeans算法进行简单的介绍,Kmeans算法是属于无监督的学习的算法,并且是最基本、最简单的一种基于距离的聚类算法。
下面简单说一下Kmeans算法的步骤:
选随机选取K的簇中心࿰…
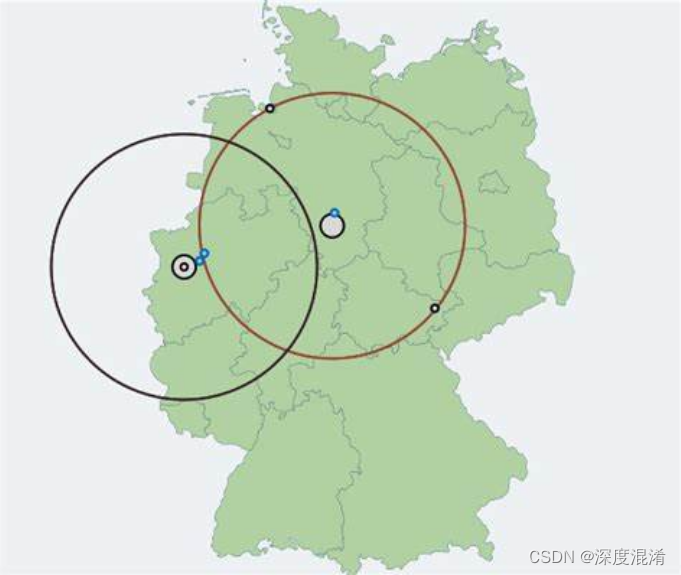
C#,K中心问题(K-centers Problem)的算法与源代码
1 K中心问题(K-centers Problem)
k-centers problem: 寻找k个半径越小越好的center以覆盖所有的点。
比如:给定n个城市和每对城市之间的距离,选择k个城市放置仓库(或ATM或云服务器),以使城市…

人工智能_机器学习078_聚类算法_概念介绍_聚类升维_降维_各类聚类算法_有监督机器学习_无监督机器学习---人工智能工作笔记0118
首先看一下什么是聚类,我们可以进入sklearn的官网去看看 可以看到这里,首先classification 这个分类我们学完了,然后就是regression回归我们也学完了对吧,其实我们现实生活中的,大部分问题就是 这两种问题就可以解决了. 然后我们再来看一个: clustering,这个就是聚类对吧.聚类算…

K-Means:K均值聚类算法
下面通过一个案例简单介绍K-Means算法的简单流程:
>>点击下面的这张图片可以看得很清楚>> 通过上述案例可以比较清晰地理解K-Means算法,下面上代码:
测试数据:testSet.txt, 同一行的两个数据之间用tab分…
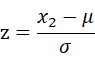

机器学习 复习四 聚类
无监督学习 衡量:处理不规则形状,噪音点
相似的物品成一类,不相似的物品不成一类
K-Means
步骤: 随机选K个聚集点 每个数据被赋值最近聚集点类别 使用每个聚集中心点更新 重复直到聚点不再移动 返回K个中心点坐标
优点&#x…

【AI视野·今日CV 计算机视觉论文速览 第278期】Mon, 30 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Mon, 30 Oct 2023 Totally 50 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Image Clustering Conditioned on Text Criteria Authors Sehyun Kwon, Jaeseung Park, Minkyu Kim, Jaewoong Cho, Ernest…
关于距离,K-means,层次聚类,密度聚类以及谱聚类
目录
相似度/距离
k-Means算法
衡量聚类(轮廓系数)
层次聚类
密度聚类
谱聚类 之前博客中讲的模型基本上都是分类以及回归模型,他们都是属于有监督学习的,意为所有的样本都有一个结果值提供,我们所要做的就是在原…

【文本聚类】一篇文章弄懂三种聚类算法(K-Means,Agglomerative,DBSCAN)
概述
▶ 常用的聚类方法
核心思想常见算法划分聚类将给定的数据集,采用分裂法划分为K个类K-Means, CLARANS层级聚类根据数据点之间的相似度创建一颗有层次的树Agglomerative(聚合), Divisive(分裂)密度聚类当一片区域内的数据点的密度大于某个阀值,则认…
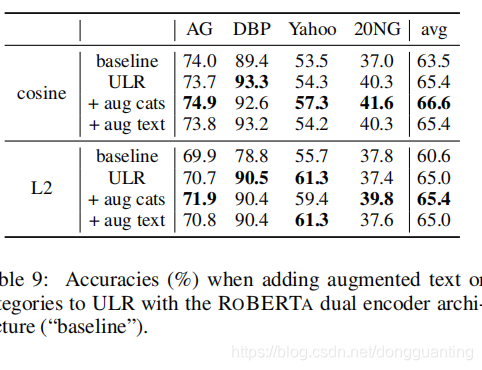
【ACL 2021】《 Unsupervised Label Refinement Improves Dataless Text Classification》阅读笔记
【ACL 2021】《 Unsupervised Label Refinement Improves Dataless Text Classification》阅读笔记
英文标题:Unsupervised Label Refinement Improves Dataless Text Classification 中文翻译:无监督的标签细化改进无数据文本分类 原文链接: https://a…
Coursera-MachineLearning-Week8编程题目整理
pca.m
sigma (X*X)./m; %计算Sigma
[U,S,V] svd(sigma); %进行奇异值分解projectData.m
Ureduce U(:, 1:K); %提取前k列
for i 1:size(X,1) %遍历所有样本x X(i,:); %获取样本Z(i,:) x*Ureduce; %进行降维
endrecoverData.m
for i 1:size(Z,1) X_rec(i,:) Z(…

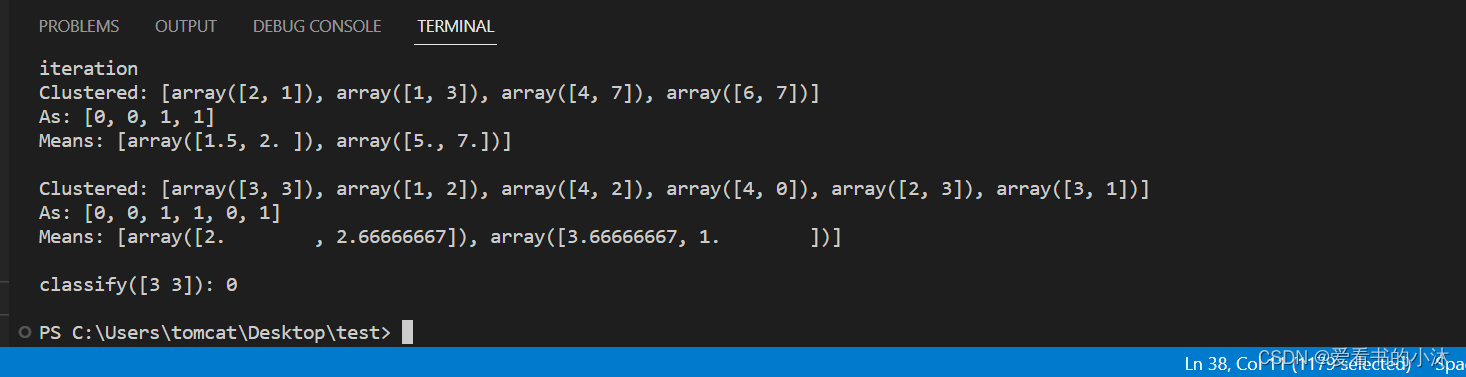
k-means++算法的c++实现
k-means是机器学习领域一种基本的聚类算法,是k-means算法的增强版,与k-means算法的唯一区别就在于初始点的选择上。众所周知, 通常情况下,k-means选择初始点都是以一种随机的方式选择的,选择的初始点的好坏,…

MVO优化DBSCAN实现聚类
目录
一、MVO
1.基本概念
2.算法原理
3.算法的优缺点
4.算法流程
二、DBSCAN
1.基本概念
2.算法原理
3.算法的优缺点
4.算法流程
5.参数设置
6.MATLAB代码
三、MVO优化DBSCAN实现聚类
参考文献 一、MVO
1.基本概念
MVO算法的思想启发于物理学中多元宇宙理论,通…

玩转大数据15:常用的分类算法和聚类算法
前言
分类算法和聚类算法是数据挖掘和机器学习中的两种常见方法。它们的主要区别在于处理数据的方式和目标。 分类算法是在已知类别标签的数据集上训练的,用于预测新的数据点的类别。聚类算法则是在没有任何类别标签的情况下,通过分析数据点之间的相似性…
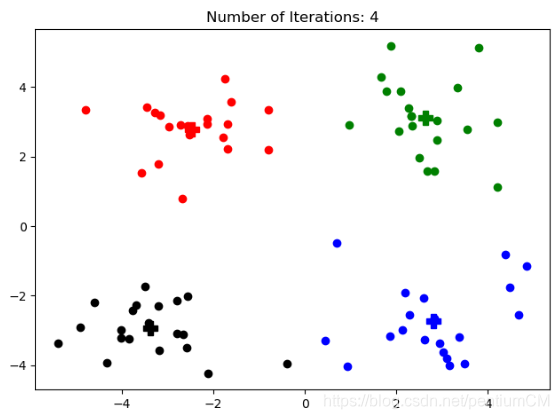
机器学习 — K-Means、K-Means++ 原理及算法实现
文章目录机器学习 — K-Means、K-Means 原理及算法实现一、K-Means1. 概念2. K-Means算法思想3. K-Means特点4.K-Means算法实现二、K-Means1.概念2.K-Means算法思想3.K-Means特点4.K-Means算法实现三、总结机器学习 — K-Means、K-Means 原理及算法实现
一、K-Means
1. 概念 …

聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut
聚类算法是ML中一个重要分支,一般采用unsupervised learning进行学习,本文根据常见聚类算法分类讲解K-Means, K-Medoids, GMM, Spectral clustering,Ncut五个算法在聚类中的应用。 Clustering Algorithms分类
1. Partitioning approach: 建立…
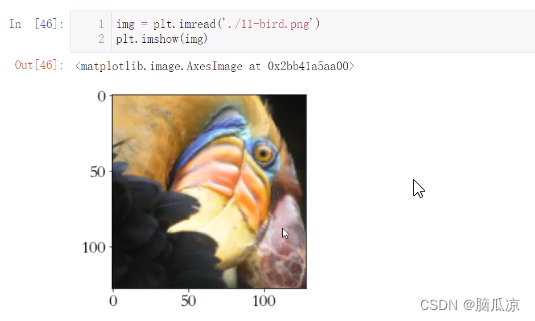
人工智能_机器学习084_使用聚类算法_提取图片主要颜色_对图片进行聚类提取特征_对图片进行压缩---人工智能工作笔记0124
然后我们再来看之前我们说聚类是可以进行数据压缩的对吧,现在我们用聚类KMeans进行
对图片主要特征颜色提取,来压缩图片 首先看一下我们准备的一张图片 首先导包,显示一下图片
import numpy as np 导入数学计算包
import matplotlib.pyplot as plt 导入画图工具包
import …
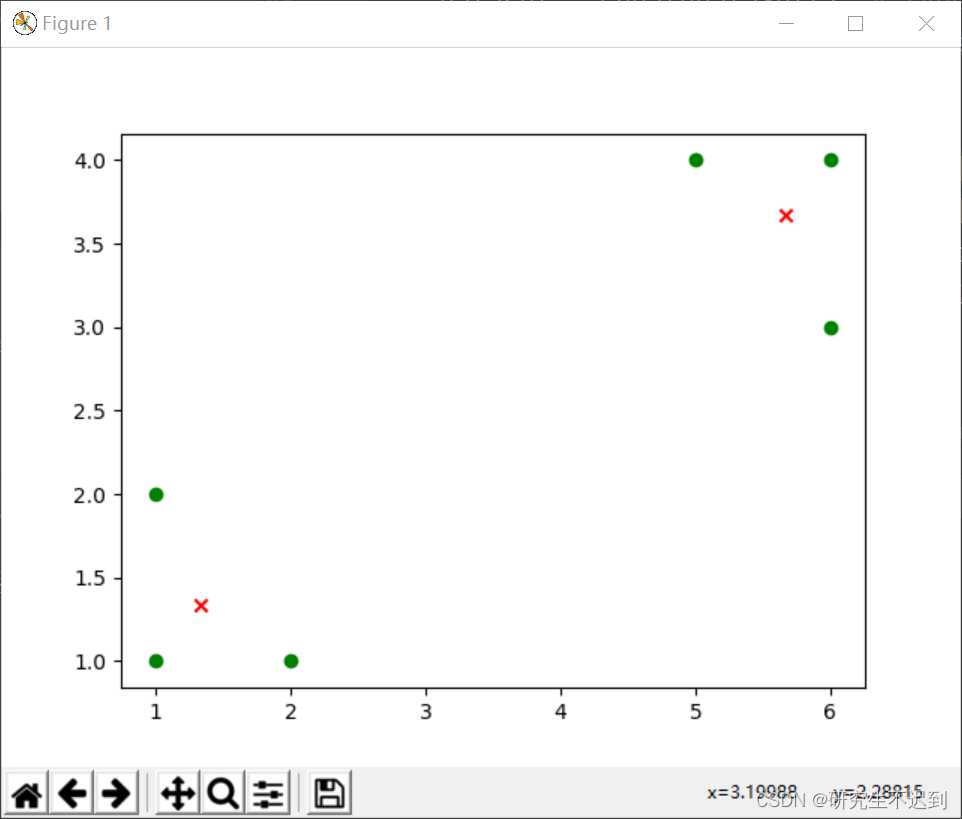
K-means聚类算法原理及python具体实现
文章目录1 快速理解1.1 算法步骤1.2 一个例子2 K-means步骤详解2.1 K值的选择2.2 距离度量2.3 新质心的计算2.4 停止条件3 K-means算法实现3.1 创建数据集3.2 kmeans函数实现3.2.1 random.sample(sequence, k)3.2.2 np.all()3.2.3 np.any()3.3 Updata_cen 函数实现3.3.1 np.arg…
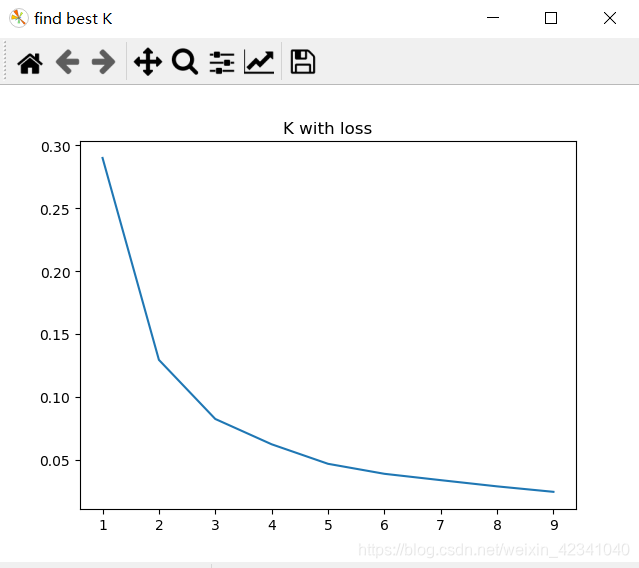
《统计学习方法》聚类代码实现
层次聚类假设类别之间存在层次结构,将样本聚到层次化的类中层次聚类又有聚合或自下而上、分裂或自上而下两种方法。
聚合聚类开始将每个样本各自分到一个类;之后将相距最近的两类合并,建立一个新的类,重复此操作直到满足停止条件…